Automated insight (automated descriptive analytics)
Introduction
This article describes how we can avoid the process of generating and manually inspecting hundreds of reports, which often lead to incorrect decisions being made based on misleading or insignificant findings. This manual process is often referred to as Business Intelligence (BI). While some Business Intelligence activities are highly valuable, many are not and can be counterproductive.
Instead we automatically identify information which is either significant or unusual using a Bayesian network. This process is called automated insight and is an automated form of descriptive analytics.
The advantages of this approach are as follows:
- Avoid the expensive report generation process.
- Avoid the expensive burden of maintaining many reports.
- Explore the equivalent of hundreds of thousands of possible reports automatically.
- Avoid mistakes often made when interpreting the significance of reports.
- Not restricted to considering 2 columns of data at a time (2D report) or 3 columns of data at a time (3-D report).
- Make it possible to automate the resulting decision making process on the back of any findings.
Manual insight life-cycle (business intelligence)
A typical life-cycle of manual insight extraction, performed by humans reviewing static or dynamic reports, comprises the following:
- Questions are asked by the CEO, CFO, CTO, CDO, or other parties with a hunch (we will abbreviate with CXX).
- Lots of people have lots of ideas resulting in a backlog of questions (We call it a 'Hunch backlog').
- The backlog is prioritized according to the seniority of the requester.
- Analysts use tools to visualize data in 2D or 3D (basically counting visualized).
- They find it hard to decide which information is significant. They also develop hunches about which information is salient.
- They also sometimes make mistakes. This means repeating the process, or worse CXX making incorrect decisions. (Bear in mind that not all mistakes will lead to a bad outcome, but companies do not like unknown risk).
- Analysts report their findings to CXX stakeholders.
- CXX ignore the findings because they don't trust the analysts (this distrust may be well founded), and an original hunch is followed anyway. Sometimes the original question was irrelevant due to the financial gains or losses involved.
Semi-automated insight life-cycle
An alternative approach to the manual insight approach is to let the data do the talking. The life-cycle now looks as follows:
- An algorithm is used to build a model of the data. For example a Bayesian network.
- An algorithm interrogates the model for significant patterns or unusual (anomalous) patterns. This step is equivalent to hundreds of analysts at work, but the algorithm can discern what is important and does not make mistakes.
- Key findings are surfaced to human decision makers.
Moving from manual insight extraction to the semi-automated process is a big step forward.
Importantly it has the advantage that the decision makers can quickly change tack. For example, often the top piece of insight will already be known. With the simple click of a button, the analysis can be repeated conditioned on what is known (equivalent to filtering or excluding data), live in front of the board. (The equivalent of 1000s of reports being manually inspected in front of their eyes.)
Building a model
In order to perform automated insight, you first need to build a model. A model is typically built from data, but could be based on expert opinion or a mixture of both.
With Bayesian networks there are many different models you can build.
If you do not have a particular target variable in mind (e.g. Purchase={True,False}) a good start is to build a Mixture model (cluster model).
The advantages of this type of model are as follows:
- They can capture multivariate patterns. (They can consider interactions between many columns of data at once).
- They can capture hidden relationships in the data.
Alternatively if you do have a particular target variable in mind (e.g. Purchase={True, False}) a good start is to build a Mixture of Naive Bayes model, which is simply a mixture model with additional links from the target (variable of interest) to each other variable (excluding the cluster variable). This will have all the advantages of the Mixture model described above, but is biased towards predicting a particular variable.
You can build many other different types of model to suit your scenario.
Extracting insight
To automatically extract insight from a model, you can use the Auto-insight tool shown below or the companion Pattern Analysis tool.
The auto insight tool interrogate the model and rank the resulting insight (patterns). You can either rank the insight by Largest Patterns or by Anomalous patterns depending on what you are trying to achieve.
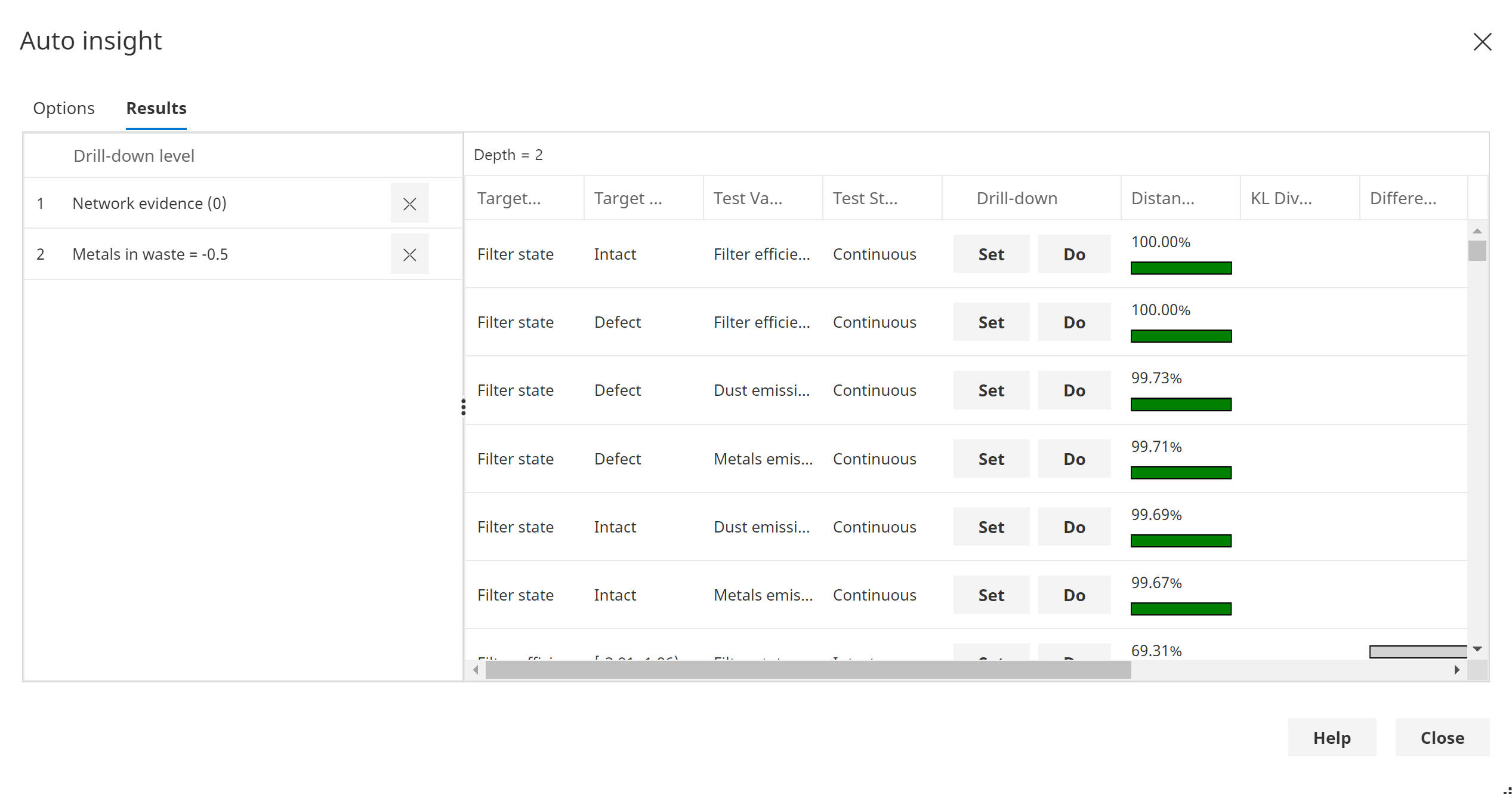
The auto-insight tool also allows dynamic drill down, which is a great exploratory tool during a board meeting.
The companion Pattern Analysis tool provides a simpler view which is great for understanding cluster for segmentation or for discriminating between different states (e.g. Fault/No Fault).
Fully automated insight life-cycle
The problem with the semi-automated life-cycle is that we still have human decision makers involved. I.e. people are still in the loop. A fully automated insight life-cycle is similar to the semi-automated life-cycle except the insight is consumed by a machine. This is typically a decision support system which could make use of Evidence Optimization or Decision graphs.
In fact the insight and decision support systems may well co-exist, allowing them to make cost based decisions together.
To find our more please see the following help articles.