Auto insight
For a tutorial please see Auto insight tutorial.
Introduction
Auto Insight simplifies the process of understanding how different states of a variable compare within your model. For instance, if you have a variable like "Purchase" with states "True" and "False," Auto Insight allows you to see exactly how outcomes differ when a purchase occurs versus when it doesn’t. By highlighting key differences, this tool provides quick, actionable insights that help you make informed decisions. Whether your goal is to optimize customer conversion, understand behavior patterns, or improve model accuracy, Auto Insight’s intuitive approach ensures you can easily interpret variable state comparisons with clarity and confidence.
For a mixture model, one cluster might perform much better or worse than others, so we might be interested in how this cluster differs from the others.
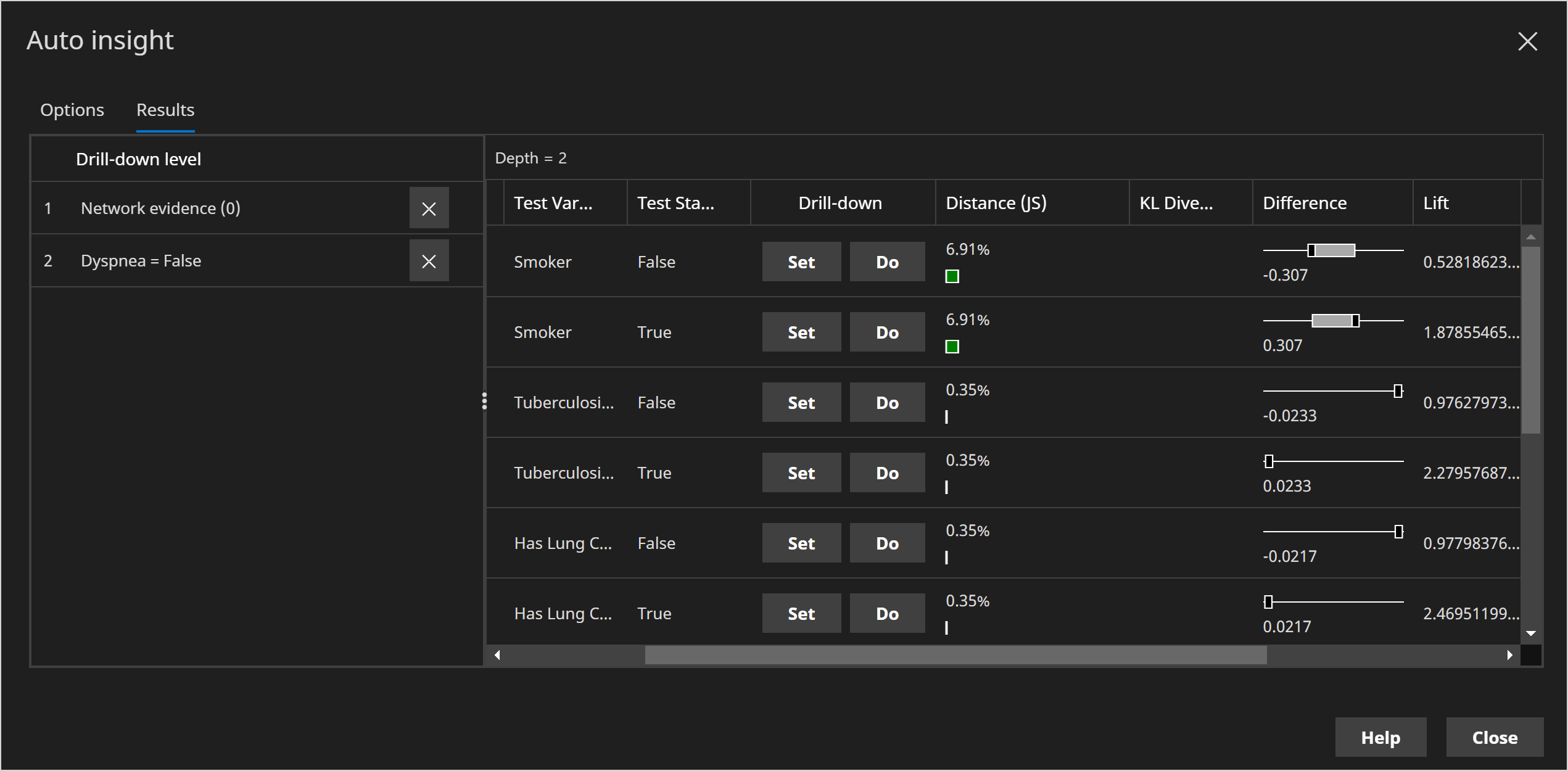
The auto insight viewer allows us to easily identify the key differentiators, which can be sorted by Difference in order to detect the largest patterns, or Lift to identify anomalies.
Drill-down
Once the first key differentiating states have been identified, you can then perform drill-down, by clicking on the Set button (or Do for interventions), and the calculations will be repeated, this time with additional evidence set on that state.
Use network evidence
When Use network evidence is selected, any evidence set on the network before opening the auto insight viewer will be used in the subsequent calculations.
Output columns
- Target variable: The variable whose states you are analyzing.
- Target state: This is the target variable state you are comparing to all the other states of the target variable.
- Test variable: A variable which may or may not change significantly between Target Variable=Target State & Target Variable = NOT Target State.
- Test state: The test variable state whose change we may be interested in
- Distance: The distance between the test distribution from when Target Variable=Target State and when Target Variable = NOT Target State.
- Difference: The difference (for discrete states only) between the test state from when Target Variable=Target State and when Target Variable = NOT Target State.
- Lift: The lift (for discrete states only) between the test state from when Target Variable=Target State and when Target Variable = NOT Target State.
- Probability: P(Test), the probability of the Test State, without evidence set on the Target.
- Probability | Target: P(Test|Target), the probability of the Test State, with evidence set on this Target state.
- Target: P(Target|Test), the probability of the Target State given the Test state.