Data map
Introduction
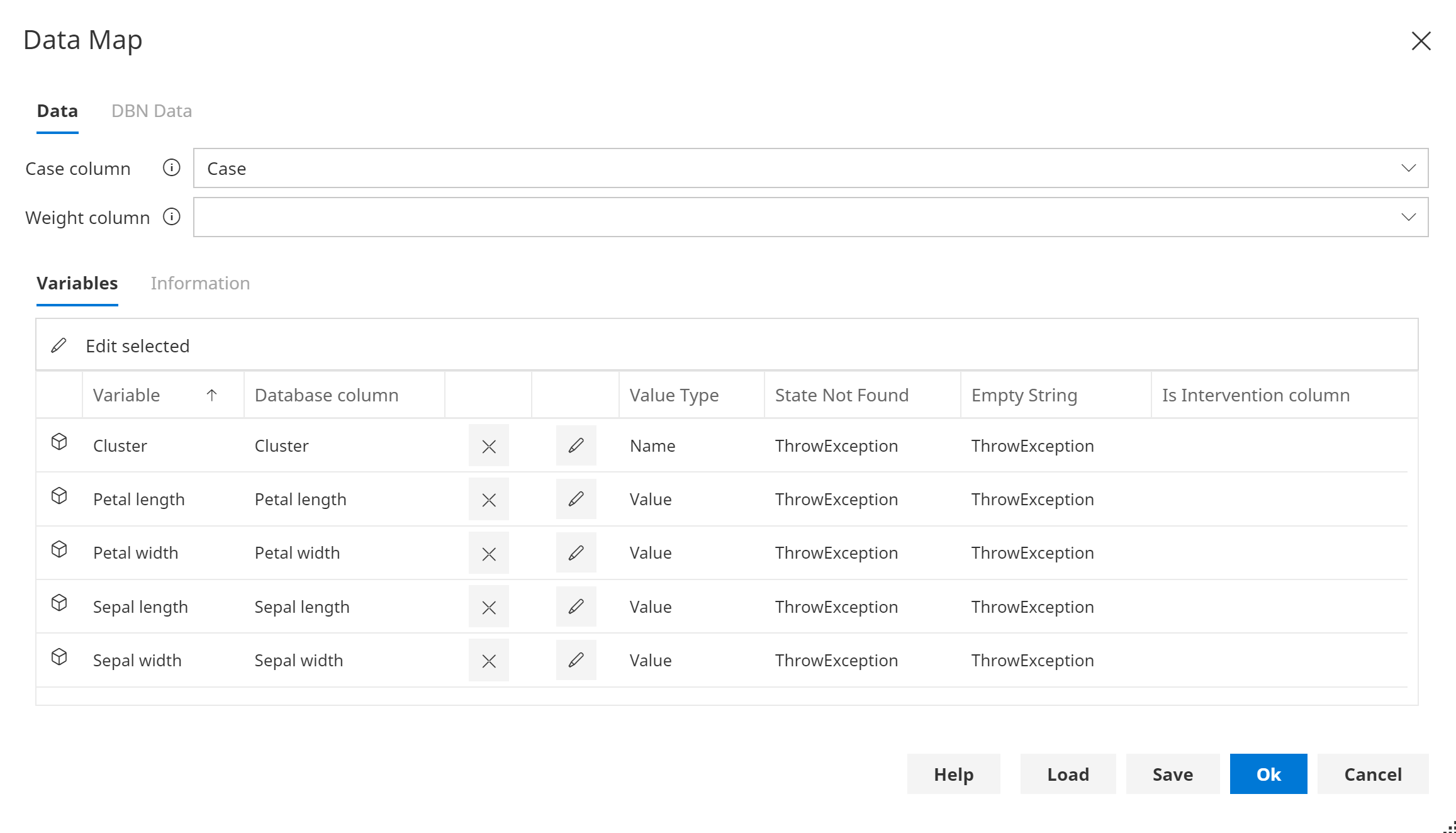
The Data Map dialog allows columns from a Data Connection, such as a database or spreadsheet, to be mapped to Variables in a Bayesian network or Dynamic Bayesian network.
Data
The Data tab corresponds to Data selected in the Data Tables window. If no Data table was selected, the tab will be disabled.
An additional tab switches between mapping Variables and defining Information Columns.
DBN Data
The DBN Data tab corresponds to DBN Data selected in the Data Tables window. If no DBN Data table was selected, the tab will be disabled.
An additional tab switches between mapping Variables and defining Information Columns.
Variable Map
Variables can be mapped to Database columns, by changing the Database Column drop down. When the dialog opens, Variables are automatically mapped to Database columns with the same name.
To clear a mapping for a Variable, click the Clear button.
Value Type
The Value Type associated with a Variable Map, defines the type of data to expect.
Value Type
The Value Type column allows you to map from data to evidence in different ways.
Name - maps text to the name of a state in a discrete variable
Value - maps numeric values to continuous variables, or maps to discrete variables with State Values (e.g. selects a state based on its numeric interval).
Index - maps a zero based integer to the index of a state in a discrete variable
State Not Found
When mapping variables to data columns there is an option called State Not Found which determines the action to take when a value in the database does not match the state of a discrete variable. By default an error is raised, however when this option is set to Missing Value the value that does not match is treated as missing.
This is useful when a network is trained on one data set, and then predictions are made on another which contains values that were not present in the training data set. For example during training a variable Country might include {United States, United Kingdom}. When the network is then tested on unseen data or deployed to make predictions on live data we might encounter a new value for Country such as {Japan}. Setting the State not found option to Missing Value will treat {Japan} as a missing value.
If these previously unseen values become common in the data then it might be wise to retrain the network on the new data.
Information Columns
Information columns are database columns that provide useful information, but are not mapped to any Variables.
The Data Map window will attempt to auto detect whether an information column is discrete or continuous. This can be changed in the data map dialog, and persisted using the Save button. The distinction between discrete and continuous is important when charting and performing other analyses.
The Information tab is only enabled when information columns are relevant to the current operation. For example the Information tab is enabled when loading data into Data Explorer but not for Parameter learning.
Case Id Column
A Case Id Column can be used for the following:
- To differentiate between separate Time Series/Sequences, in DBN Data.
- To associate each Time Series/Sequence within DBN Data, with a particular row in non temporal data.
- Easy data identification/labeling.
Case Ids are optional if:
- There is no DBN data
- There is only a single Time Series/Sequence, and no corresponding non DBN data
A Case Id Column can be of any comparable type, such as an Integer, Date, Time, Double, etc...
Cross validation
Cross validation is used by certain algorithms in Bayes Server to determine the best structure of a network, such as which links to add, or the number of latent states to include.
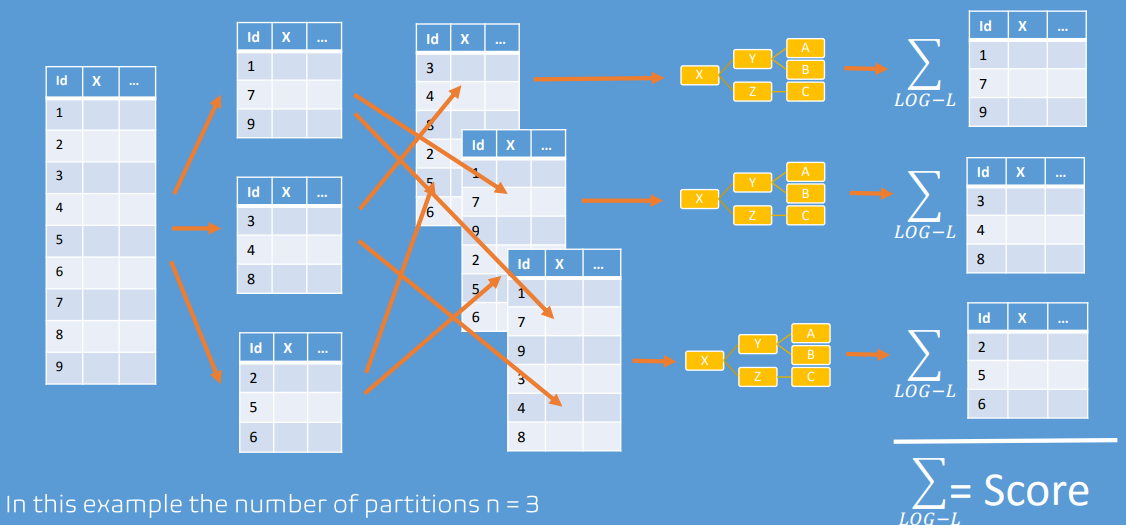
As illustrated in the image below, cross validation splits a data set D into a number of partitions. For each partition p, we build a model on (D excluding p) and test on p. Once we have done this for each partition, we have obtained test statistics across the entire data set as if that data were unseen. This provides a robust way to determine the efficacy of competing structures.
In the Bayes Server User Interface, a partition column is required to specify which partition a row falls into, whereas in the API the partitions can be specified more flexibly using code.
Partition Column
For algorithms that perform Cross validation a partition column is required.
For example, some structural learning algorithms, and the Cluster count algorithm require a partition column.
Cross validation splits a dataset into a number of partitions. The partition column is used to determine which partition each record (case) belongs to.
A partition column can contain any of the following:
- A unique id (integer). (partition = id modulo partitionCount)
- The zero based index of the partition (i.e. 0 corresponds to the first partition, 1 to the second and so on)
- For API users the partition can be arbitrarily constructed, but each record (case) should only belong to one partition.
An example of using a unique id column is shown below.
| Partition | X | Y |
|---|---|---|
| 1 | 2.34 | 5.43 |
| 2 | 3.43 | 6.21 |
| 3 | 45.4 | 23.2 |
| 4 | -2.4 | 4.7 |
| 5 | -3.23 | -2.1 |
| 6 | 12.3 | 14.6 |
| ... | ... | ... |
| 400 | 8.22 | 2.4 |
| 401 | 6.21 | 1.4 |
| 402 | 4.2 | 12.3 |
| 403 | -6.2 | 5.7 |
| ... | ... | ... |
Weight Column
The Weight Column is optional, and allows a support/probability (or any positive value) to be associated with a case.
This is often used when a dataset contains large numbers of duplicate rows. Duplicate rows can be replaced with a single row and an associated weight, which is the number of times the row was duplicated in the original dataset.
A weight column need not contain whole numbers. It could, for example, contain a probability to be associated with a particular case. This might be useful when you want to give more weight to certain cases than others.
When using a weight column, the log-likelihood for each case will be adjusted by the weight. This will be noticeable in the log-likelihood statistic output when performing a Batch query or during Parameter learning.
Time Column
The Time Column must be specified when DBN Data is present. It defines the order of Temporal/Time Series values. There are two ways the Time Column can be specified:
- If the option Time is zero based index is true, the values in the Time Database column represent a Time index, such that a value of 0 maps to t=0, 120 maps to t=120 etc...
- When the option Time is zero based index is false, this indicates that the Time Database column contains values that are comparable, such as Dates, Times, Doubles, or Integers etc... During an operation that requires data, Bayes Server will first order these values, and then treat them as consecutive time values mapping to t=0, t=1, t=2...
Is Intervention Column
An additional column in a data source can be used to indicate that evidence is or is not an intervention (do evidence) for a particular variable.