Batch query
Introduction
A Batch query allows multiple cases to be queried.
The resulting queries can be charted, used to generate summary statistics, used to generate a confusion matrix or lift chart for classification analysis, used to evaluate regression models, evaluate anomaly detection trends and more.
If you are trying to predict a variable, but have the expected predicted value in the data set, do not map it to the variable. Instead include the data by checking it on the Information tab. This will allow you to perform classification analysis if you export the data. An alternative to this approach is to use the Retract Evidence feature, which will assume no evidence is present for the variable being predicted.
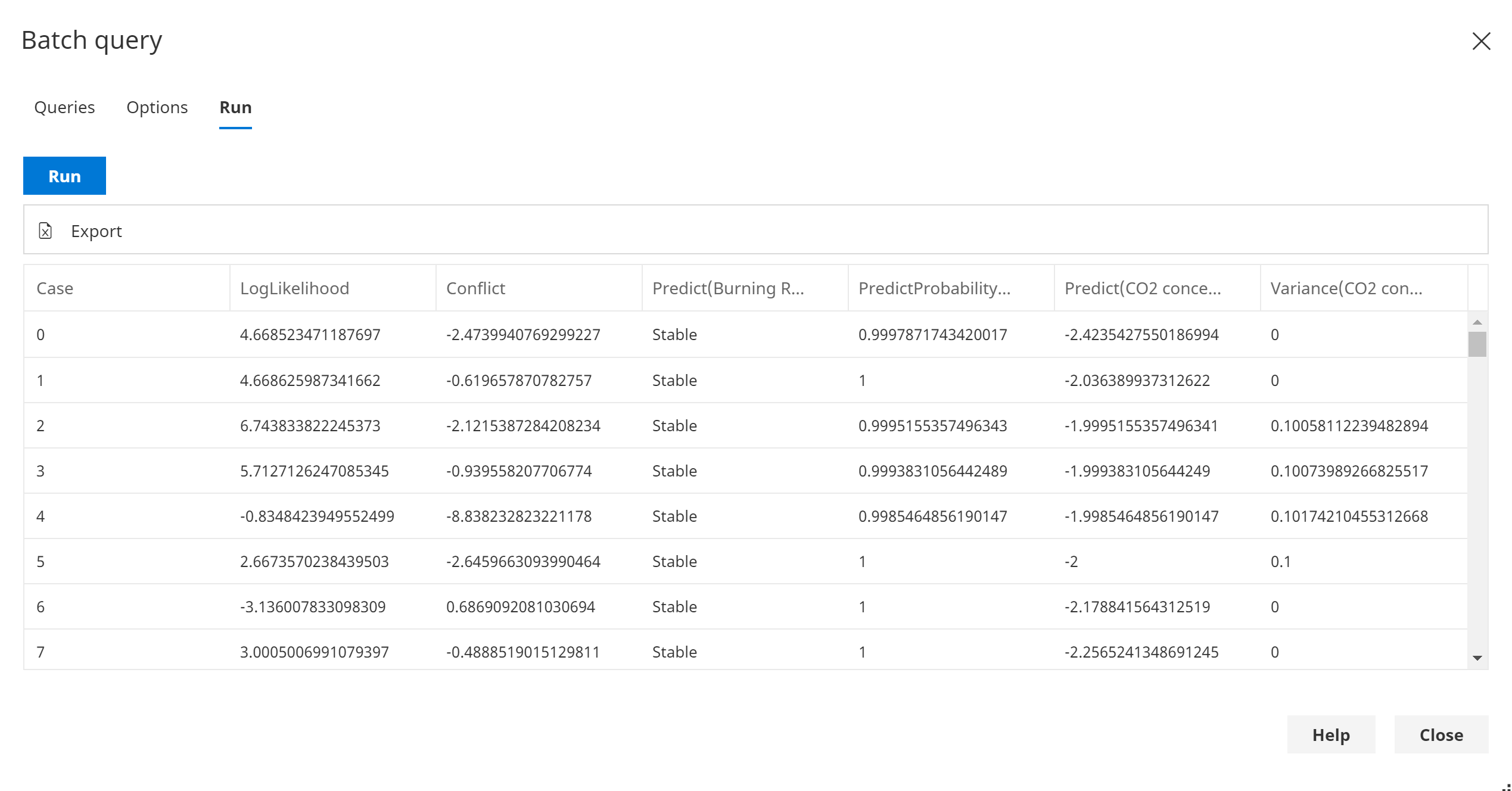
Queries
The following list describes each query type.
- LogLikelihood - outputs the log-likelihood for the case.
- Likelihood - outputs the likelihood for the case.
- Conflict - outputs the conflict for the case.
- Sequence length - outputs the maximum time series/sequence time (zero based) for the case.
- Evidence count - outputs the number of variables that have evidence set for the case.
- Predict([Variable]) - outputs the prediction for the [Variable] given the evidence in the case. For discrete variables, this is the most likely state.
- PredictProbability([Variable]) - outputs the probability of the associated prediction for the discrete [Variable] given the evidence in the case, i.e. the probability of the most likely state.
- PredictProbability([Variable]=[State]) - outputs the probability that a discrete [Variable] is in a particular [State] given the evidence in the case.
- PredictVariance([Variable]) - outputs the predicted variance for a continuous [Variable].
- [Variable] - outputs the case evidence for a [Variable].
- [Information] - outputs an information column defined in the Data Map window.
Retract evidence
Consider the prediction of variables X, Y and Z, where all variables have data mapped to them. If the Retract button is checked, then the prediction of X will ignore any evidence set on X, using only evidence set on Y and Z. The prediction of Y will only use evidence set on X and Z, and the prediction of Z will only use evidence set on X and Y. See Retract evidence for more information.
State Values
When the State values check box is set to true, the output for any discrete variables with a suitable
BayesServer.StateValueType are the state values, rather than the state name or index.
Note that this option overrides the State Names option.
State Names
When the State Names check box is set to true, the output for any discrete variables is the name of the discrete state. When set to false, the output is the zero based index of the state.
Note that this option may be overridden by the State Values option.
Skip if query error
This option affects the outcome if an error occurs during the batch query. When true, processing will continue, but cases with errors are not output. A certain number of errors will be displayed at the end of processing. When false, the output stops at the point of the first error encountered.
Most probable explanation
Most probable explanation (MPE), also known as max propagation, computes the most probable configuration of variables that do not have evidence. See Most probable explanation for more information.
Temporal options
Allow the minimum and maximum times to be set, when running batch time series queries on networks with temporal nodes (i.e. dynamic Bayesian networks).
Algorithm
This option determines the algorithm used, when calculating the batch query.
Export
To perform further analysis or visualize the results, you can export the batch query results.