Cluster count
Introduction
Cluster Count determines the number of clusters (states) for a discrete latent variable (cluster / mixture) in a Bayesian network.
The process uses cross validation, and evaluates the log-likelihood for a series of different cluster counts.
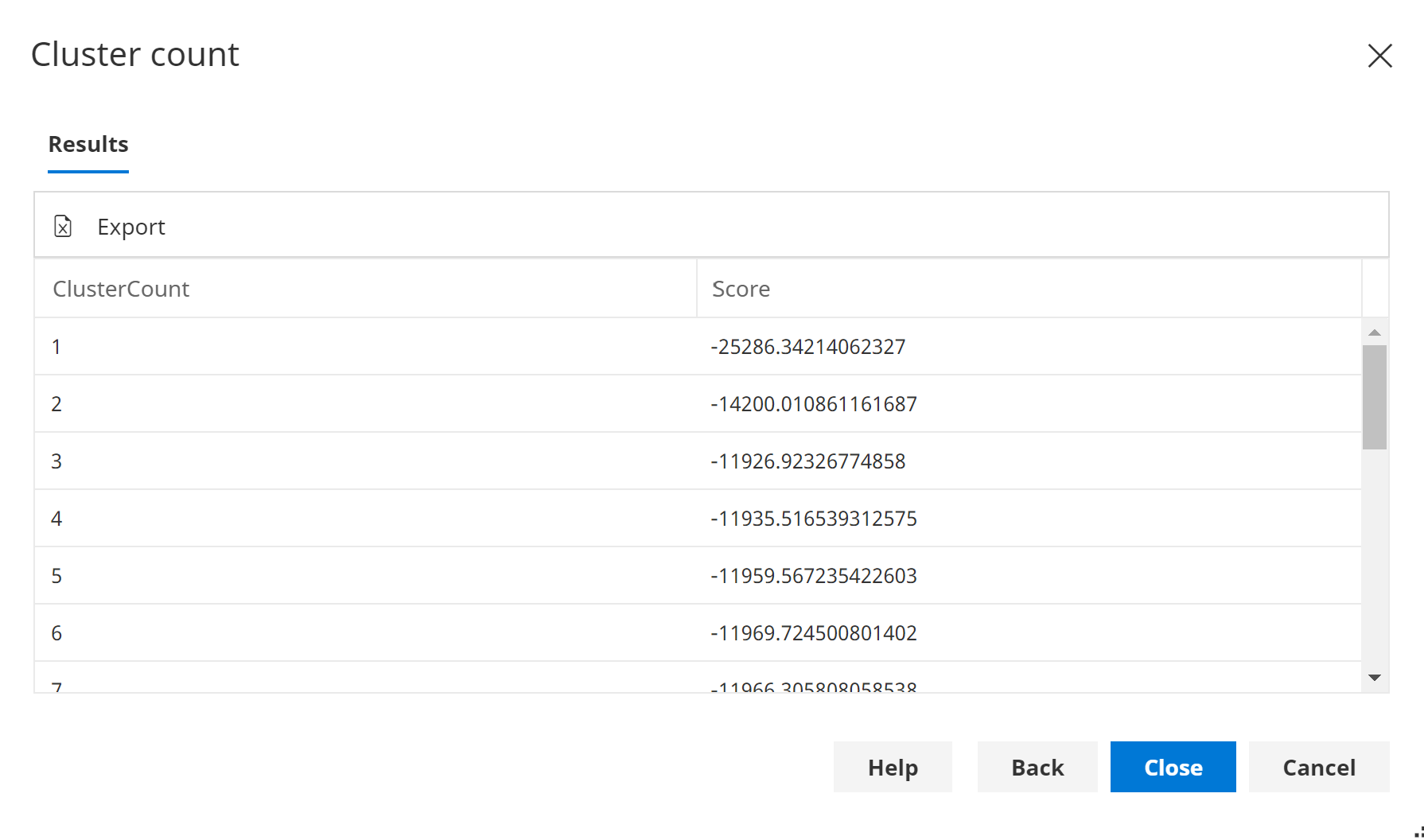
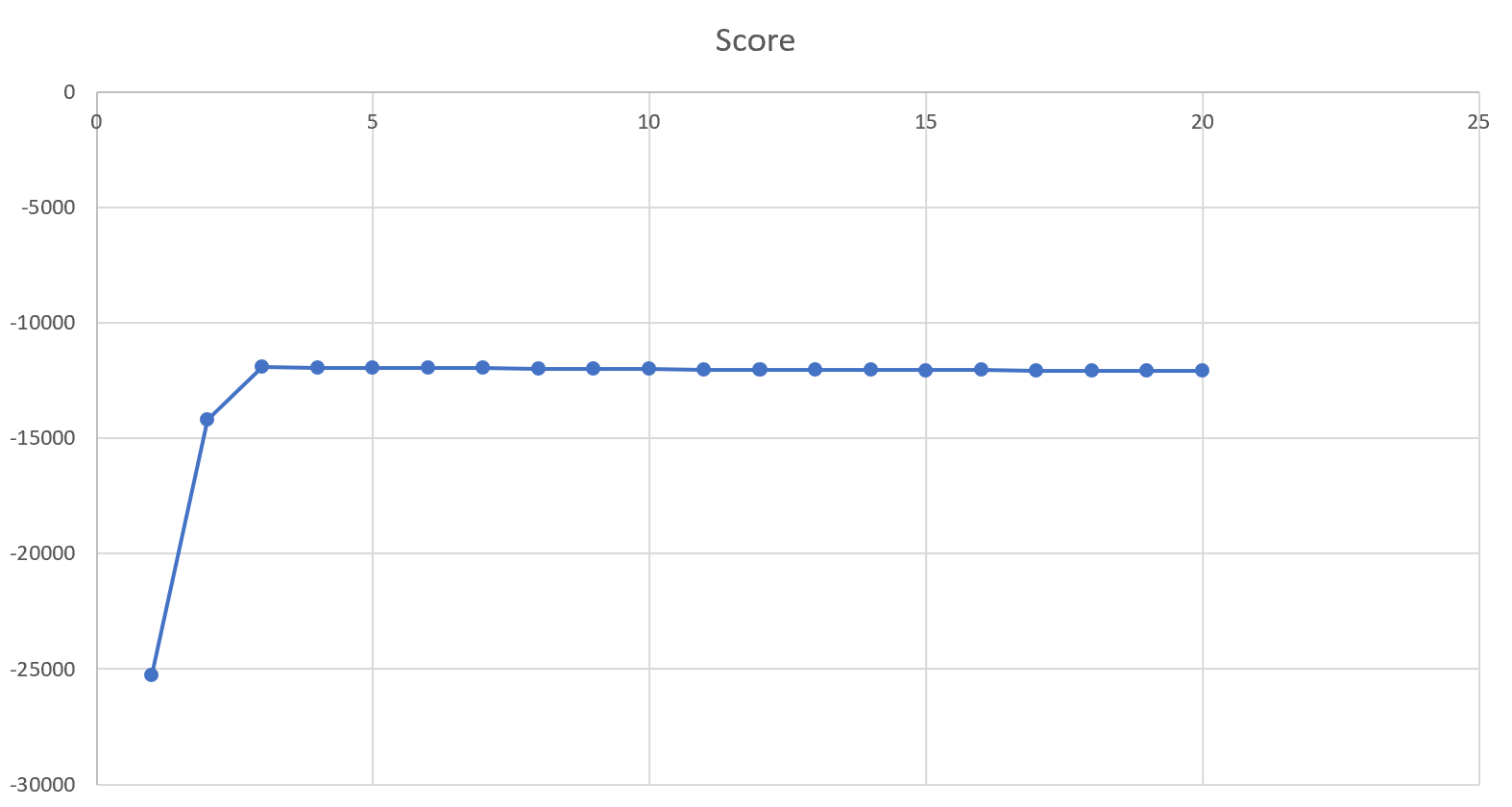
The Cluster counts and scores can be exported to a tool, such as Excel, in order to generate a plot such as the following:
Pre-requisites
Unlike the Clustering Structural learning algorithm, the cluster count tool requires a network with at least one existing discrete latent variable and links should already have been added.
Bayes Server supports networks with multiple latent variables.
Algorithm
In order to determine a suitable number of clusters, cross validation is used. The data is split randomly into a configurable number of partitions. For each partition p, a models is learned on (data - p), and the log-likelihood is evaluated on the unseen data p. The log-likelihood is then summed over each partition, resulting in an overall score.
This score is calculated for each configurable cluster count, and the scores plotted.
A higher score is generally preferred, but so are fewer clusters. Typically the best cluster count occurs before the score no longer increases significantly to justify the additional parameters.
Once a suitable number of clusters has been determined, close the Cluster count window and update the number of states in the cluster variable.
A cluster count of 1 is included by default to test the hypothesis that the cluster variable is not required at all.