Impact analysis
Since version 7.18
For a tutorial please see Impact tutorial.
Impact analysis is a process used to assess how different sets of evidence affect a particular target variable, often referred to as the "Hypothesis". This method allows researchers and decision-makers to understand the influence of specific data on an outcome, offering valuable insights into which pieces of evidence are most critical in shaping the result.
Through impact analysis, one can identify individual pieces of evidence that significantly alter the target. By focusing on the effects of each data point, users can determine which inputs drive the greatest change, helping prioritize information that has the strongest impact. Conversely, by examining the impact of excluding certain data points, impact analysis reveals which pieces of evidence, if left out, lead to notable shifts in the outcome. This helps pinpoint potentially essential evidence that supports the overall hypothesis.
Additionally, impact analysis can evaluate combinations of evidence, showing how specific subsets, whether included or excluded, affect the target variable. This feature is particularly useful for assessing interdependent data points and their collective impact on the hypothesis. Overall, impact analysis provides a structured approach to understanding evidence relevance, empowering users to make data-informed decisions and refine their strategies for more accurate and effective results.
To summarize, impact analysis can be used to:
- See which individual pieces of evidence change the target the most
- See which individual pieces of evidence, when excluded, change the target the most
- See which subsets of evidence which, when included or excluded, change the target the most.
A complimentary tool is Log-likelihood analysis which can help determine which pieces of evidence are anomalous.
The target variable (V) is also often referred to as the hypothesis variable.
Support
| Variable type | Hypothesis | Evidence |
|---|---|---|
| Discrete | Yes | Yes |
| Continuous | Yes | Yes |
| Hybrid | Yes | Yes |
We use the term None to refer to the case when none of the evidence (being analyzed) is included. We use the term All to refer to the case when all of the evidence (being analyzed) is included.
Subsets
The subsets to consider are generated by looking at all possible combinations of evidence, subject to the following constraints.
Max evidence subset size
The number of items of evidence in each subset.
Subset method
When Subset method is set to Include, evidence on variables in the subset is included, but not other evidence variables (being analyzed).
When Subset method is set to Exclude, all evidence is used, except for those in the subset.
Statistics
For each evidence subset, impact analysis calculates a number of statistics:
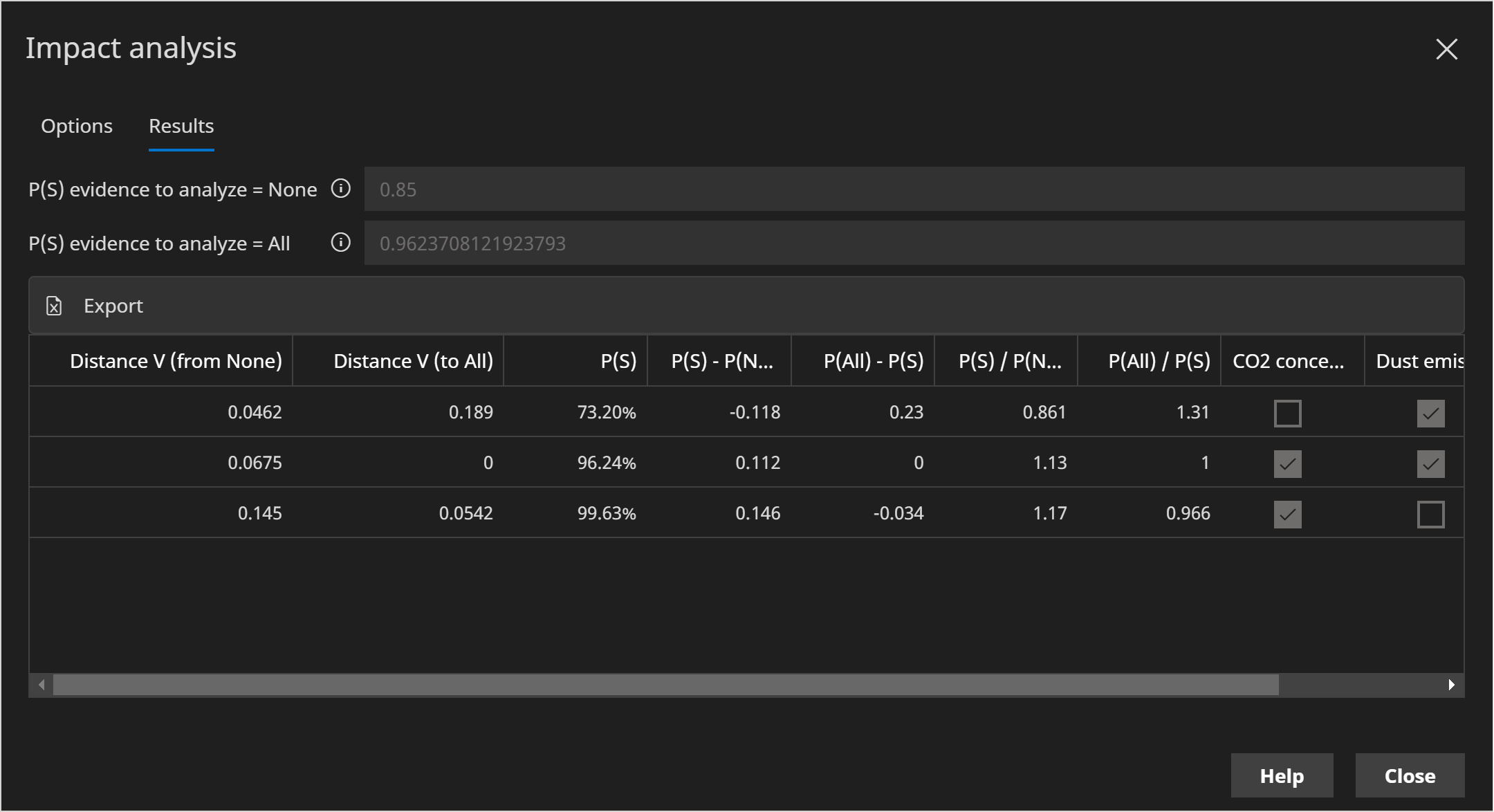
Distance V (from None)
The Kullback-Leibler divergence D(P||Q) from the target (V) query without evidence (Q) to the current combination (P).
This tells us how different the target (V) is between the current subset evidence and no evidence.
Kullback-Leibler divergence (to All)
The Kullback-Leibler divergence D(P||Q) from the target (V) query with the current subset of evidence (Q) to all evidence (P).
This tells us how different the target (V) is between all evidence and the current subset evidence.
P(S)
When a discrete target state (S) is included, this reports the probability of that state given the current evidence subset.
P(S) - P(None)
When a discrete target state (S) is included, this reports the difference between the probability of that state given the current evidence subset and no evidence.
P(All) - P(S)
When a discrete target state (S) is included, this reports the difference between the probability of that state given All the evidence and the current evidence subset.
P(S) / P(None)
When a discrete target state (S) is included, this reports the ratio between the probability of that state given the current evidence subset and no evidence.
This is also known as the Normalized Likelihood in impact analysis.
P(All) / P(S)
When a discrete target state (S) is included, this reports the ratio between the probability of that state given All the evidence and the current evidence subset.