In-sample anomaly detection
Since version 7.23
Introduction
In-Sample anomaly detection can be used to remove anomalous records from training data. This results in a training set that is considered Normal which can subsequently be used to build models.
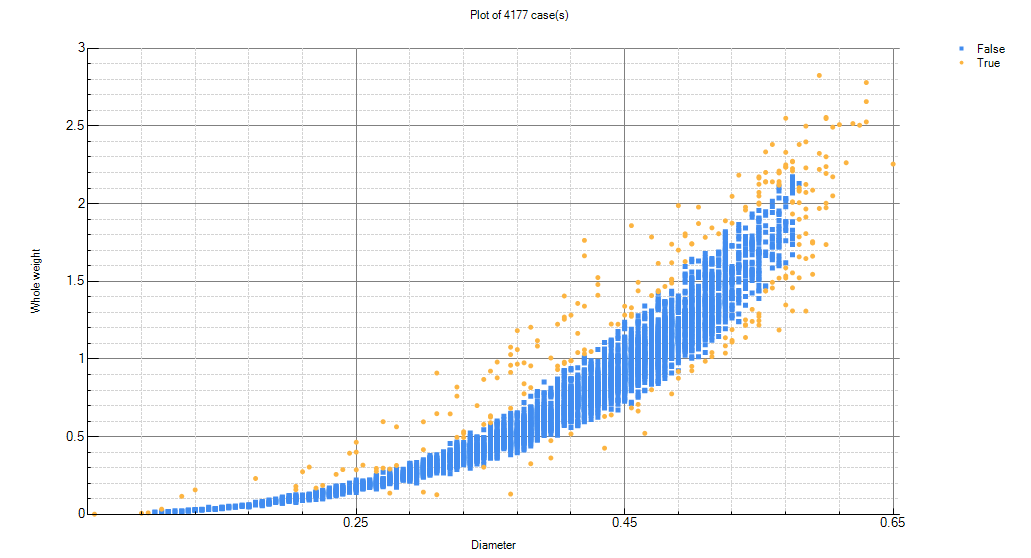
Un-Supervised anomaly detection
Having a Normal model is particularly useful for building unsupervised anomaly detection systems.
Sometimes it is possible to manually exclude anomalous data for training. For example, if the anomalies have been recorded by a maintenance system. However, past anomalies may not be recorded at all, dates may be inaccurate, etc...
Model structure
In order to run the in-sample anomaly detection algorithm you will need an existing network structure. Any Bayesian network structure can be used, but the structure should be capable of capturing complex relationships.
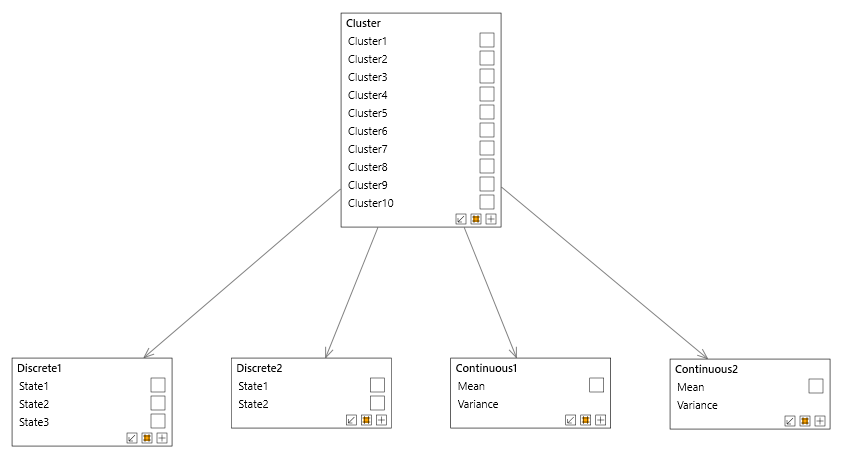
Mixture model
If you are unsure which network structure to choose, a good baseline choice is a Mixture model. An example of a Mixture model is shown below. The Cluster node is called a Latent Variable and allows the model to capture complex relationships. The other nodes map to your data, and can be added using Add nodes from data. To determine a suitable number of clusters you can use Clustering Structural learning algorithm or the Cluster count tool.
If you decide to use a mixture model to remove anomalous data from the training data, this does not mean you have to use the same model structure thereafter. It can be thought of as a pre-processing step.