Parameter learning
In this tutorial we demonstrate the process of parameter learning, which uses data to determine the distribution(s) for one or more nodes in a Bayesian network.
You can also specify the distributions manually. In fact, you can learn some nodes from data and elicit some manually if required.
Generate tutorial data
We will generate data from a known network, and then delete the distributions for that network before proceeding with learning.
In the Bayes Server User Interface, open the Waste network from the Start page (or from File/Open).
From the Application main tab, click Data Sources.
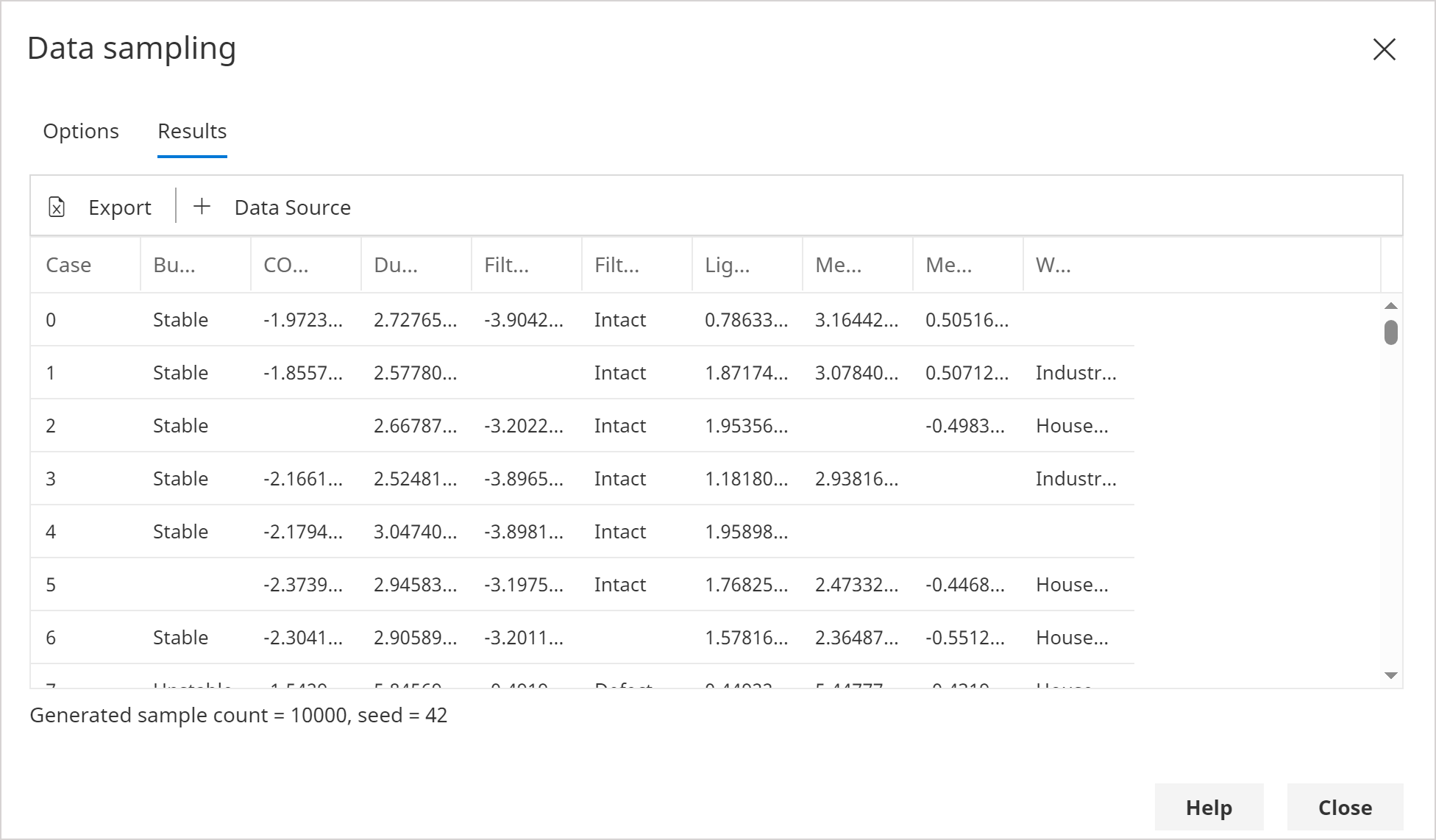
Click Generate -> Generate Custom. This will launch the Data Sampling dialog.
Under Options expand the .. more items to display further options.
Change the Sample Count to 10000.
Change the Missing Data Probability to 0.05. This will result in 5% of the data having missing data, which is fully supported during parameter learning.
Click Run.
In the Results you should notice that some of the data values are missing as expected.
Click the + Data Source button.
Close any dialogs until you return to the Network Viewer.
Note that parameter learning supports missing data and latent variables.
Delete existing distributions (optional)
By default, parameter learning will overwrite existing distributions, although this is configurable per node.
For this tutorial, we will delete all the existing distributions, to show that we have in fact learned the distributions.
You can choose not to learn certain node distributions. You can also choose not to map certain columns of data to nodes.
Repeat the following steps for each node in the network.
Click to select the node.
From the Build main tab, click Distributions -> Edit distribution(s).
From the toolbar, click Delete -> Delete Distribution.
Parameter learning | Map Data
From the Build main tab, click Distributions and then Parameter Learning.
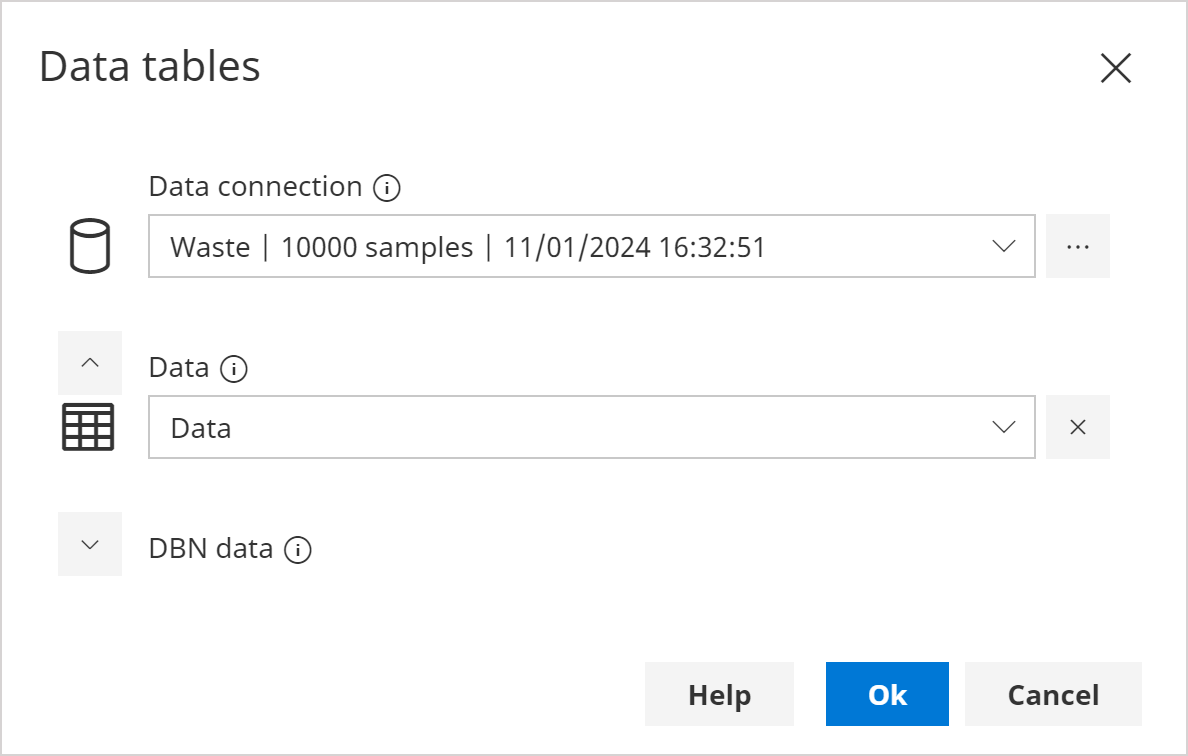
In the Data Tables dialog, in the Data Connection drop down, select the 10k Waste samples that were just generated.
In the Data drop down, select Data.
Click Ok.
In the Data Map dialog, check that all variables have been automatically mapped to data, then click Ok. This will launch the Parameter Learning dialog.
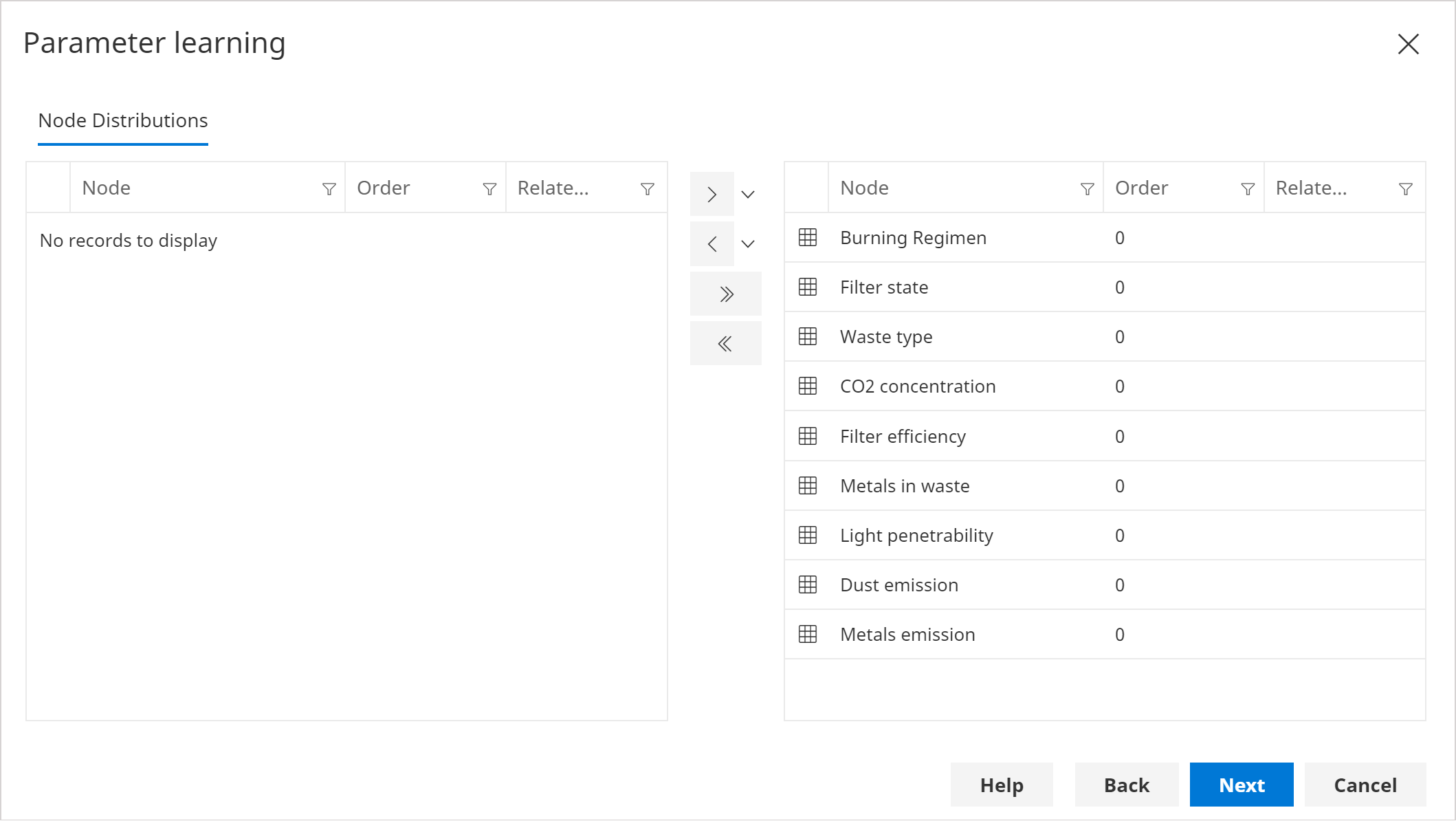
In the Node Distributions page, check that all the nodes are selected as shown below, then click next.
infoIn some cases, you may not wish to learn all the distributions. For example, if some have been elicited by experts.
In the Parameter Learning Options page, leave all the defaults, then click next.
infoFor information on the many options, hover over the information icon next to each option.
In the Run page, click the Run button to start learning.
infoSince our data had missing data, the algorithm will iterate a number of times. This would also be the case if any latent variables were present.
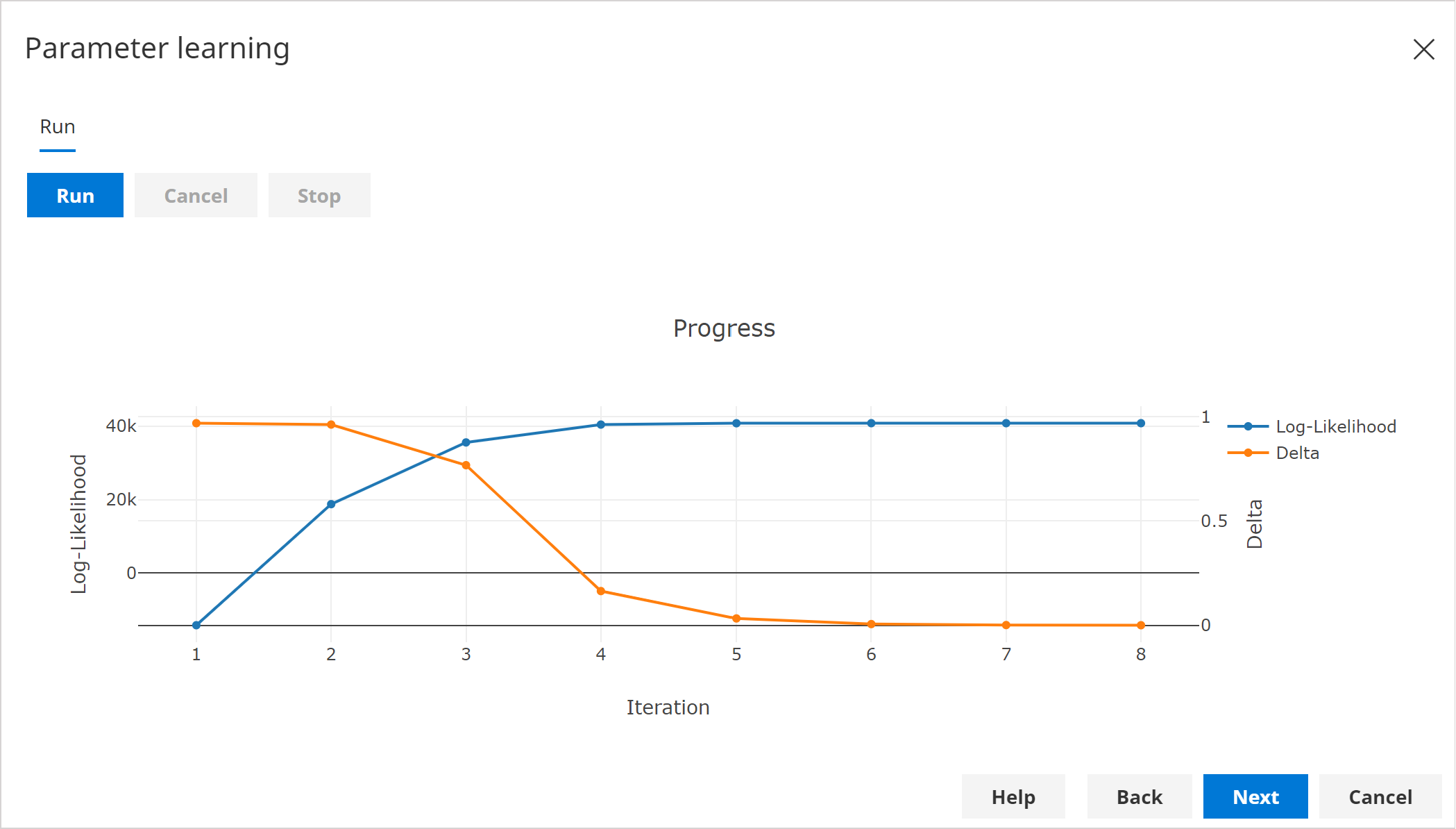
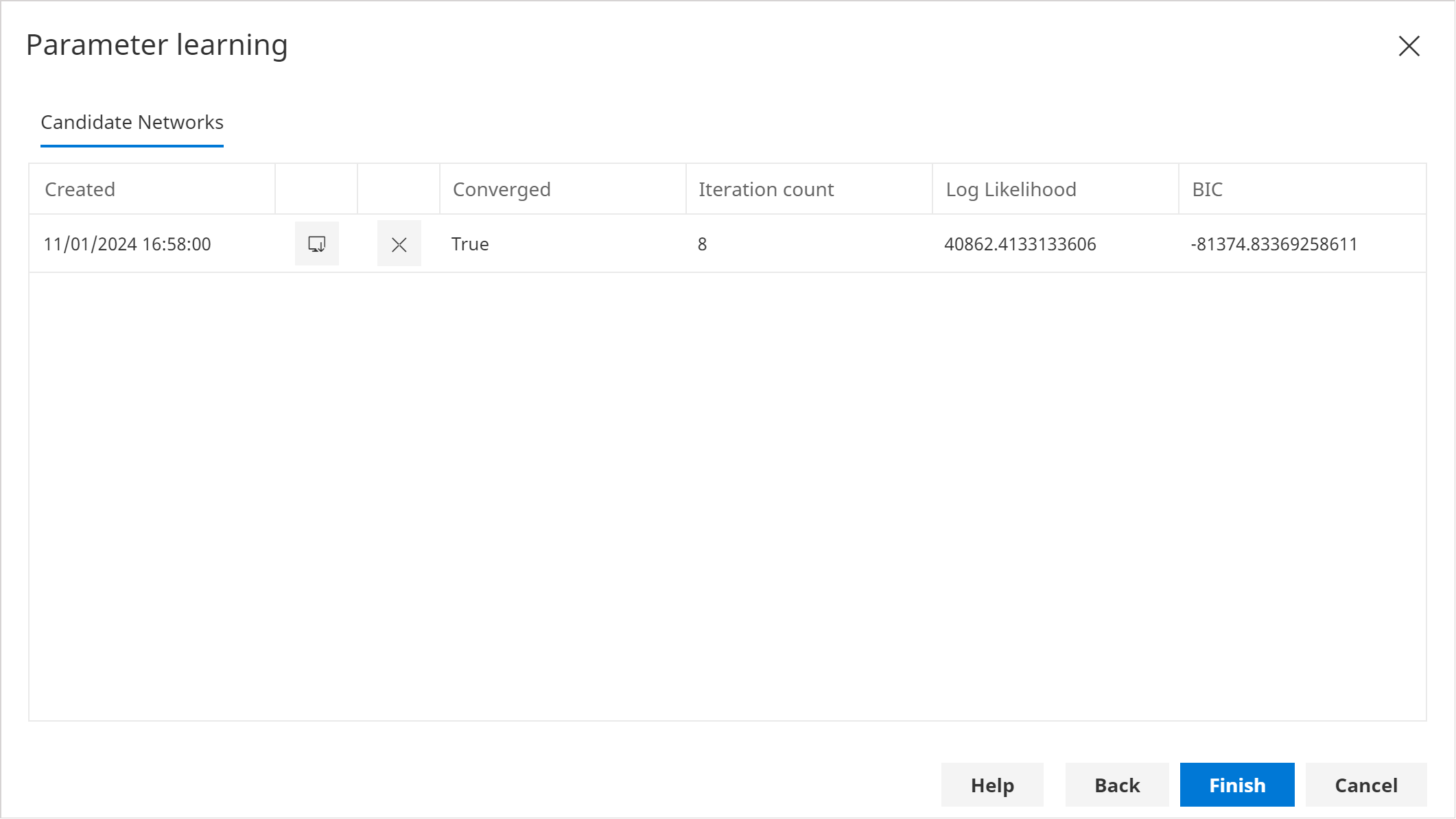
In the Candidate Networks page, there will be a single entry, which should look similar to below:
infoBecause parameter learning is non-deterministic when missing data or latent variables are present, your candidate network might be slightly different.
 info
infoBecause parameter learning is non-deterministic, you may wish to run the parameter learning process multiple times, and then pick a candidate that is similar to others (stable).
Click Finish. This will copy the new node distributions to the existing network. (This can be undone using the Undo functionality).
From the Query tab on the main menu, click Requery to re-query the network with the new distributions. (It is often easier just to set and then remove some evidence rather than refreshing).
If you compare the new distributions to the original network (e.g. open an additional instance of the User Interface), you should find the distributions are similar.