Parameter learning
Introduction
Parameter learning is the process of using data to learn the distributions of a Bayesian network or Dynamic Bayesian network.
Bayes Server uses the Expectation Maximization (EM) algorithm to perform maximum likelihood estimation, and supports all of the following:
- Learning both discrete and continuous distributions.
- Learning with missing data (discrete or continuous).
- Learning on multiple processors.
- Learning a subset of nodes/distributions.
- Learning with noisy nodes.
- Advanced initialization algorithm.
- Learning both Bayesian networks and Dynamic Bayesian networks. (e.g. Learning from Time Series data).
Not all variables have to be mapped to data columns. Any variables that are not mapped are unobserved (have missing data) during the learning process.
Learning
The Stop option, stops the learning process, however does generate a candidate network, albeit one that has had fewer iterations of learning.
If the Reset check box is checked when learning starts, all distributions are first reset to their original values (i.e. the values when the Parameter Learning dialog was opened).
When learning has completed without converging, sometimes it is useful to continue learning without starting from scratch. To do this, first ensure that the Reset and Initialize check boxes are not checked, then run again.
Distributions
Filtering
The distributions to be learned can be filtered.
By default all distributions are learned, however sometimes distributions are already known, or have been estimated by experts.
Distribution Options
There are a number of options which can be set, both for the algorithm and for each distribution being learned.
Initialize
The Initialize check box, determines whether or not distributions are initialized from the data, before learning begins.
This allows learning with nodes whose distributions have not yet been specified.
Individual distributions can override this setting.
You can also select the initialization algorithm to use. Random will randomly sample data to initialize distributions whereas Clustering uses a sophisticated clustering algorithm to initialize any latent variables. The Clustering initialization algorithm typically produces better solutions in less time.
Stopping
The learning algorithm used by Bayes Server is an iterative algorithm. The Max Iterations text box can be used to limit the number of iterations performed.
At each iteration during learning, the change in the distribution parameters is calculated. If the change is less than the value in the Tolerance text box, the algorithm does not perform any further iterations.
Concurrency
The value in the Concurrency text box, determines the maximum number of processors that are used during parameter learning.
As this value increases, so does the memory required. This is because multiple inference engines are created to process any queries required during learning.
Advanced options
For information about the Prior options, consult the following pages in the Bayes Server API help:
BayesServer.Learning.Parameters.Priors.ContinuousBayesServer.Learning.Parameters.Priors.DiscreteBayesServer.Learning.Parameters.Priors.IncludeGlobalCovarianceBayesServer.Learning.Parameters.Priors.SimpleVariance
A Seed can be specified to initialize the random number generator used by the learning algorithm. This option should not be used if Concurrency is greater than 1.
Algorithm
During parameter learning, queries may be executed. This is known as inference. The Algorithm can be changed on the options page.
The default inference algorithm is optimized for learning parameters.
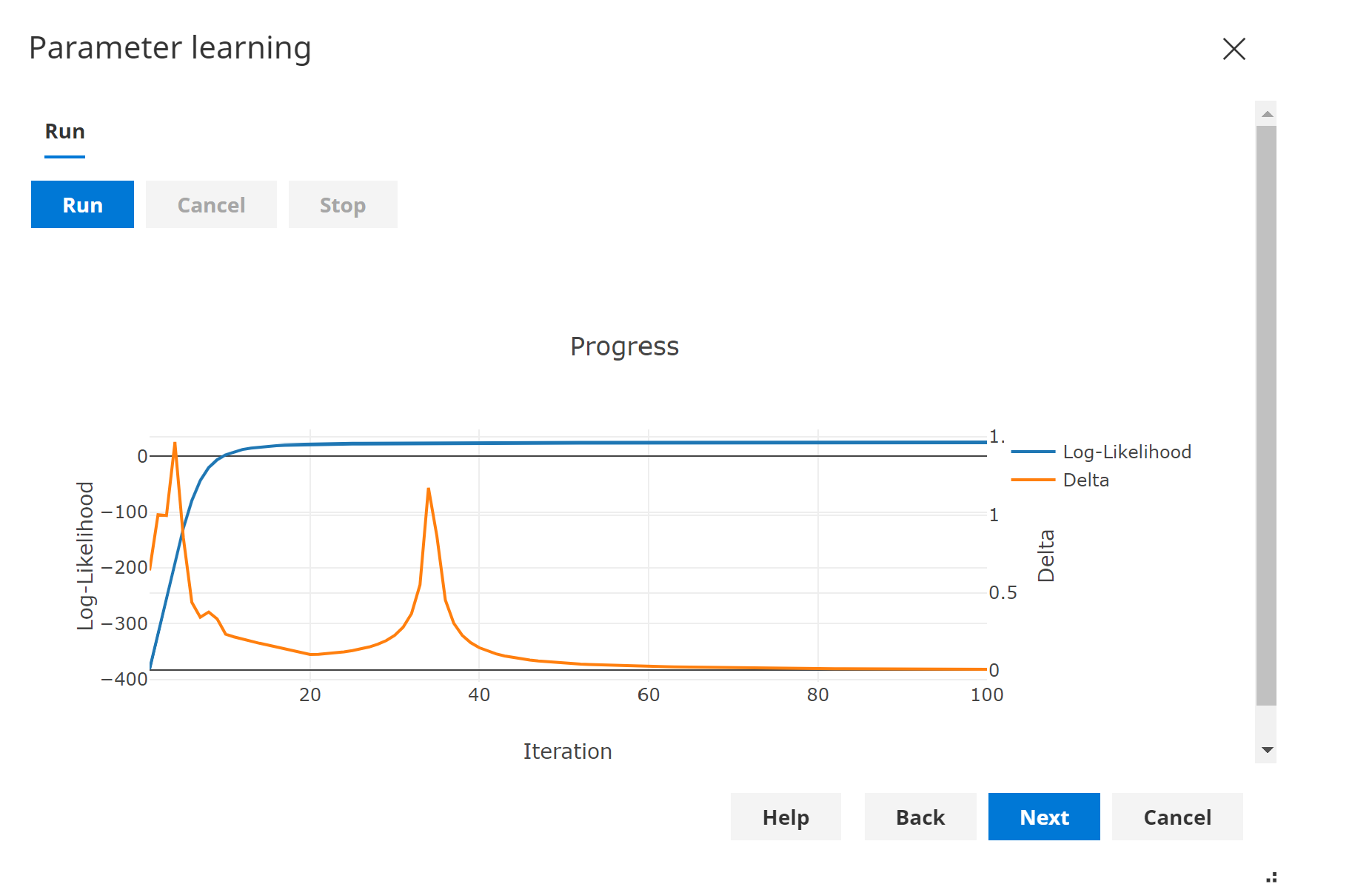
Charts
The Log Likelihood chart displays the log-likelihood at each iterations.
The Delta chart displays the difference in parameters between iterations.
It is normal for Delta to go both up and down. This does not indicate a problem.
Candidate Networks
Each time learning completes successfully, a candidate network is added.
Each candidate network displays the following information:
- Created - the time learning completed for this candidate network.
- Converged - indicates whether learning converged.
- Iteration Count - the number of iterations performed.
- Log Likelihood - the log likelihood of the data, given the candidate network.
- BIC - Bayesian Information Criterion (see
BayesServer.Learning.Parameters.ParameterLearningOutput.BICin the Bayes Server API).
Click on a header to sort the grid.
To delete a candidate network, select the network to delete, and click the Delete button.