Feature importance
Feature importance can be used to decide which variables are likely to influence a target variable of interest, for example a variable that you are trying to predict.
Each variable is compared to the target variable using statistical significance tests based on data.
The following features are supported.
- Comparing discrete variables
- Comparing continuous variables
- Comparing continuous and discrete variables
Defining variables
In order to perform feature selection on a data set, you must have first defined your variables/nodes. If required, these can be automatically determined using the Add nodes from data feature.
Opening
With a Bayesian network open:
- Click the Features button on the main toolbar, Data tab, Network group.
This will launch the Data tables window.
In the Data tables window, select the data you wish to use for feature selection. For more information about selecting data, see the help for the Data tables window. Once the table or table(s) have been selected, click Ok. This will launch the Data Map window. This window allows you to map data to variables in the network.
Clicking Ok on the Data Map window will launch the Feature importance window, shown below.
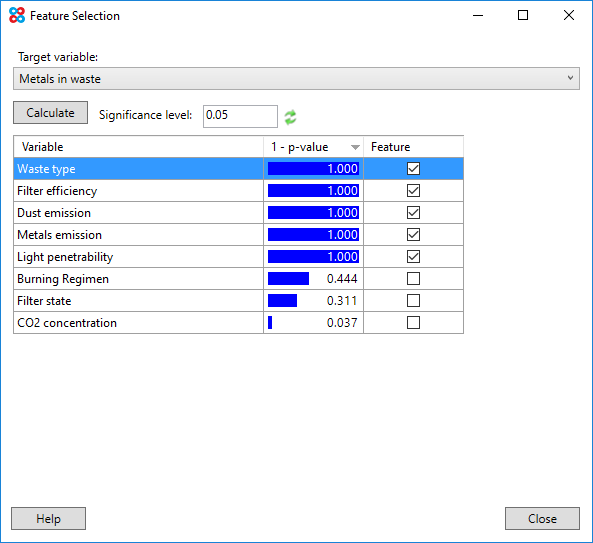
Performing feature importance
- Choose the target variable in the Target Variable drop down. This may be the variable you are trying to predict/classify.
- Click Calculate.
Variables will be shown in the table, sorted by their influence (correlation) on the target variable.
If the p-value is less than or equal to the threshold defined in the Significance level text box, if will be checked as a feature.