Variable elimination is one of the simplest algorithms which can be used to calculate queries (predictions) in a Bayesian network.
|
|
|---|
|
The process of calculating queries (predictions) is known as inference. |
 Distributive law
Distributive law
The distributive law simply means that if we want to marginalize out a variable A from a number of distributions, we can perform the calculations on the subset of distributions that contain A.
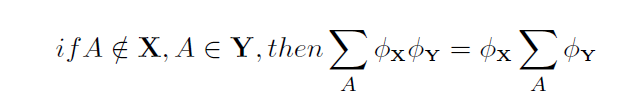
|
|
|---|
|
The equation above, reads as follows: If the variable A is not a member of the set of variables X, but A is a member of the set of variables Y, then the marginal distribution resulting from averaging out A from the product of a distribution containing X, and a distribution containing Y equals the product of the distribution containing X and the marginal distribution resulting from averaging A out of the distribution containing Y. |
Variable elimination
Consider the Bayesian network in the image below containing the nodes A,B,C and D.
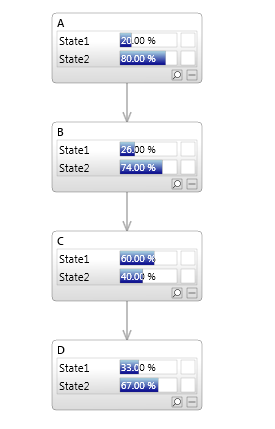
As discussed in Bayesian networks - definition, all nodes in a Bayesian network must have distributions conditional on their parents, therefore the distributions for the network above are as follows:
| Node | Distribution |
|---|---|
| A | P(A) |
| B | P(B|A) |
| C | P(C|B) |
| D | P(D|C) |
One way to calculate a query such as P(D) would be to multiply all these distributions together to form P(A,B,C,D), and then marginalize out A, then B, then C, leaving P(D).
This is likely to be very inefficient, and when the number of variables increases becomes intractable.
Instead, we can use the distributive law, so that when we marginalize out A, we only need to consider the distributions containing A, which are P(A) and P(B|A).