Classification is the process of using a model such as a Bayesian network to predict unknown values (output variables), using a number of known values (input variables).
For example we could use a classification model to diagnose a disease given a number of symptoms, or we could detect a fault in a mechanical system, based on readings from sensors.
Typically, the term classification refers to models that predict discrete variables. Regression is the term used for models predicting continuous variables. |
Classification using Bayesian networks requires that we model the relationship between the input variables and the output variables we are predicting.
If we have a dataset containing both input and outputs, of sufficient size, we can train a Bayesian network which can then be used on data containing only inputs, to predict outputs.
Expert opinion (i.e. manually specifying the model) could also be used to build or enhance a model |
Classification is a type of supervised learning, because a model is trained specifically for the purpose of predicting the output variable. |
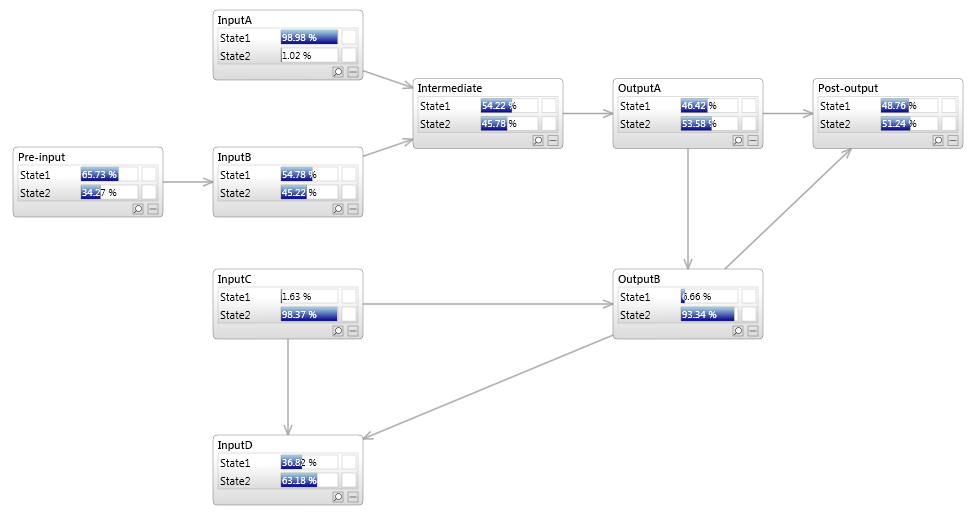
 Key features supported by Bayesian network classifiers
Key features supported by Bayesian network classifiers
Multiple inputs (multiple factors)
Multiple outputs (e.g. different faults)
Links can be from input->output or output->input
Intermediate nodes (e.g. logical nodes, divorcing)
Links between inputs
Links between output
Pre-input nodes (e.g. mixtures)
Post-output nodes (e.g. aggregate information)
The Bayesian network classifier shown below, demonstrates different design methods.