Anomaly detection, also known as outlier detection, is the process of identifying data which is unusual.
For example, anomaly detection can be used to give advanced warning of a mechanical component failing (system health monitoring), can isolate components in a system which have failed (fault detection) and can warn financial institutions of fraudulent transactions (fraud detection).
Anomaly detection can also be used to detect unusual time series. For example, an algorithmic trader may wish to know when a multivariate time series is abnormal, and use that knowledge to gain a competitive advantage.
Sometimes a univariate approach can be enough to uncover unusual behavior (i.e. considering each variable in isolation).
However, as demonstrated in Exercise - anomaly detection sometimes a multivariate approach is necessary.
Bayesian networks are well suited for anomaly detection, because they can handle high dimensional data, which humans find difficult to interpret.
There are a number of approaches to anomaly detection:
-
Supervised
-
Semi supervised
-
Unsupervised
 Supervised
Supervised
The supervised approach requires a data set containing data which is labeled either normal or anomalous/unusual. If you have sufficient data in each category, you can then build a classification model.
As shown below, a model might include one or more outputs which can be true or false, or may contain a discrete node with mutually exclusive states (or a mixture of both).
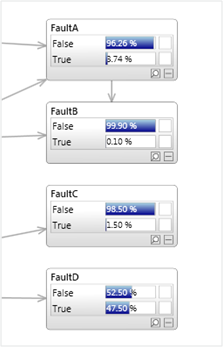
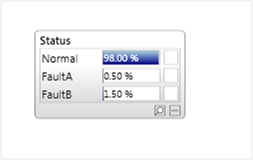
Problems with this approach occur if:
-
There is insufficient data labeled anomalous.
-
It is too difficult to manually identify anomalous data. Perhaps because the data is high dimensional, or is a complex time series or both.
-
It is too expensive to label cases manually. E.g. the costs of experts required to categorize the data.
-
Anomalies tend to be different in nature each time they occur, and therefore past anomalies do not predict future anomalies well. In practice this is often the case, therefore unsupervised alternatives exist.
Semi-supervised
The semi supervised approach uses a dataset containing only normal data. This is termed semi supervised, since the anomalous data (if any) has been removed before learning.
Once a model has been constructed, we can use Log likelihood and Conflict to perform detection on unseen data, as demonstrated in Exercise - anomaly detection.
An example output from an anomaly model is shown below:
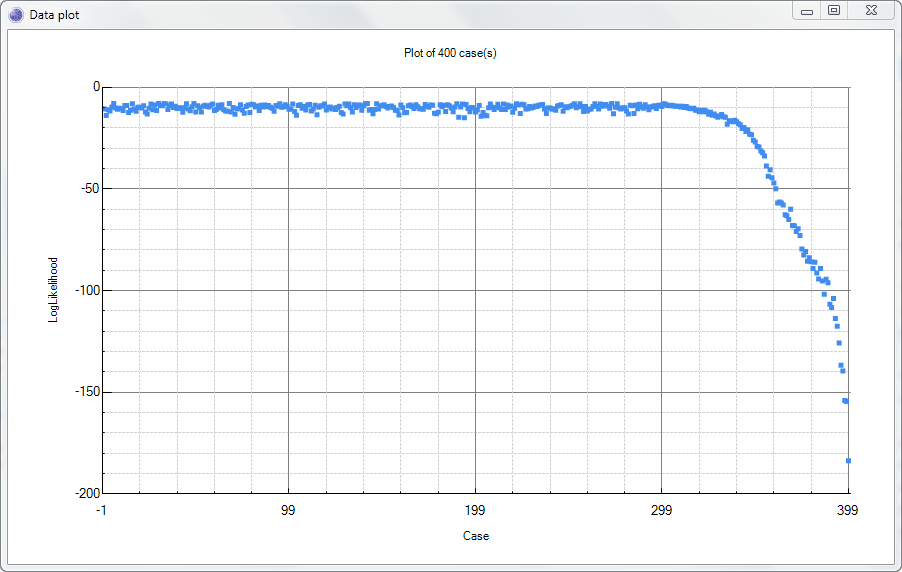
Unsupervised
Unsupervised techniques automatically build a model of the normal data, from data that contains both normal and anomalous data. The process therefore involves automatically determining which data is anomalous, or which parts of a learnt model are anomalous, in order to exclude them or label them in the final model.